Had some issues with my editor trying to convert tab-indented files to spaces, this resolves that. |
||
|---|---|---|
| _testdata | ||
| .github/workflows | ||
| benchmarks | ||
| cmd/enry | ||
| data | ||
| internal | ||
| java | ||
| python | ||
| regex | ||
| shared | ||
| .editorconfig | ||
| .gitignore | ||
| benchmark_test.go | ||
| classifier.go | ||
| common_test.go | ||
| common.go | ||
| enry.go | ||
| go.mod | ||
| go.sum | ||
| LICENSE | ||
| Makefile | ||
| README.md | ||
| utils_test.go | ||
| utils.go | ||
go-enry 


Programming language detector and toolbox to ignore binary or vendored files. enry, started as a port to Go of the original Linguist Ruby library, that has an improved 2x performance.
CLI
The CLI binary is hosted in a separate repository go-enry/enry.
Library
enry is also a Go library for guessing a programming language that exposes API through FFI to multiple programming environments.
Use cases
enry guesses a programming language using a sequence of matching strategies that are applied progressively to narrow down the possible options. Each strategy varies on the type of input data that it needs to make a decision: file name, extension, the first line of the file, the full content of the file, etc.
Depending on available input data, enry API can be roughly divided into the next categories or use cases.
By filename
Next functions require only a name of the file to make a guess:
GetLanguageByExtensionuses only file extension (wich may be ambiguous)GetLanguageByFilenameuseful for cases like.gitignore,.bashrc, etc- all filtering helpers
Please note that such guesses are expected not to be very accurate.
By text
To make a guess only based on the content of the file or a text snippet, use
-
GetLanguageByShebangreads only the first line of text to identify the shebang. -
GetLanguageByModelinefor cases when Vim/Emacs modeline e.g./* vim: set ft=cpp: */may be present at a head or a tail of the text. -
GetLanguageByClassifieruses a Bayesian classifier trained on all the./samples/from Linguist.It usually is a last-resort strategy that is used to disambiguate the guess of the previous strategies, and thus it requires a list of "candidate" guesses. One can provide a list of all known languages - keys from the
data.LanguagesLogProbabilitiesas possible candidates if more intelligent hypotheses are not available, at the price of possibly suboptimal accuracy.
By file
The most accurate guess would be one when both, the file name and the content are available:
GetLanguagesByContentonly uses file extension and a set of regexp-based content heuristics.GetLanguagesuses the full set of matching strategies and is expected to be most accurate.
Filtering: vendoring, binaries, etc
enry expose a set of file-level helpers Is* to simplify filtering out the files that are less interesting for the purpose of source code analysis:
IsBinaryIsVendorIsConfigurationIsDocumentationIsDotFileIsImageIsTestIsGenerated
Language colors and groups
enry exposes function to get language color to use for example in presenting statistics in graphs:
GetColorGetLanguageGroupcan be used to group similar languages together e.g. forLessthis function will returnCSS
Languages
Go
In a Go module,
import enry to the module by running:
go get github.com/go-enry/go-enry/v2
The rest of the examples will assume you have either done this or fetched the
library into your GOPATH.
// The examples here and below assume you have imported the library.
import "github.com/go-enry/go-enry/v2"
lang, safe := enry.GetLanguageByExtension("foo.go")
fmt.Println(lang, safe)
// result: Go true
lang, safe := enry.GetLanguageByContent("foo.m", []byte("<matlab-code>"))
fmt.Println(lang, safe)
// result: Matlab true
lang, safe := enry.GetLanguageByContent("bar.m", []byte("<objective-c-code>"))
fmt.Println(lang, safe)
// result: Objective-C true
// all strategies together
lang := enry.GetLanguage("foo.cpp", []byte("<cpp-code>"))
// result: C++ true
Note that the returned boolean value safe is true if there is only one possible language detected.
A plural version of the same API allows getting a list of all possible languages for a given file.
langs := enry.GetLanguages("foo.h", []byte("<cpp-code>"))
// result: []string{"C", "C++", "Objective-C}
langs := enry.GetLanguagesByExtension("foo.asc", []byte("<content>"), nil)
// result: []string{"AGS Script", "AsciiDoc", "Public Key"}
langs := enry.GetLanguagesByFilename("Gemfile", []byte("<content>"), []string{})
// result: []string{"Ruby"}
Java bindings
Generated Java bindings using a C shared library and JNI are available under java.
A library is published on Maven as tech.sourced:enry-java for macOS and linux platforms. Windows support is planned under src-d/enry#150.
Python bindings
Generated Python bindings using a C shared library and cffi are WIP under src-d/enry#154.
A library is going to be published on pypi as enry for macOS and linux platforms. Windows support is planned under src-d/enry#150.
Rust bindings
Generated Rust bindings using a C static library are available at https://github.com/go-enry/rs-enry.
Divergences from Linguist
The enry library is based on the data from github/linguist version v7.18.0.
Parsing linguist/samples the following enry results are different from the Linguist:
-
Heuristics for ".txt" extension in Vim Help File could not be parsed, due to unsupported negative lookahead in RE2 regexp engine.
-
Heuristics for ".sol" extension in Solidity could not be parsed, due to unsupported negative lookahead in RE2 regexp engine.
-
Heuristics for ".es" extension in JavaScript could not be parsed, due to unsupported backreference in RE2 regexp engine.
-
Heuristics for ".rno" extension in RUNOFF could not be parsed, due to unsupported lookahead in RE2 regexp engine.
-
Heuristics for ".inc" extension in NASL could not be parsed, due to unsupported possessive quantifier in RE2 regexp engine.
-
Heuristics for ".as" extension in ActionScript could not be parsed, due to unsupported positive lookahead in RE2 regexp engine.
-
As of Linguist v5.3.2 it is using flex-based scanner in C for tokenization. Enry still uses extract_token regex-based algorithm. See #193.
-
Bayesian classifier can't distinguish "SQL" from "PLpgSQL. See #194.
-
Overriding languages and types though
.gitattributesis not yet supported. See #18. -
enryCLI output does NOT exclude.gitignoreed files and git submodules, as Linguist does
In all the cases above that have an issue number - we plan to update enry to match Linguist behavior.
Benchmarks
Enry's language detection has been compared with Linguist's on linguist/samples.
We got these results:
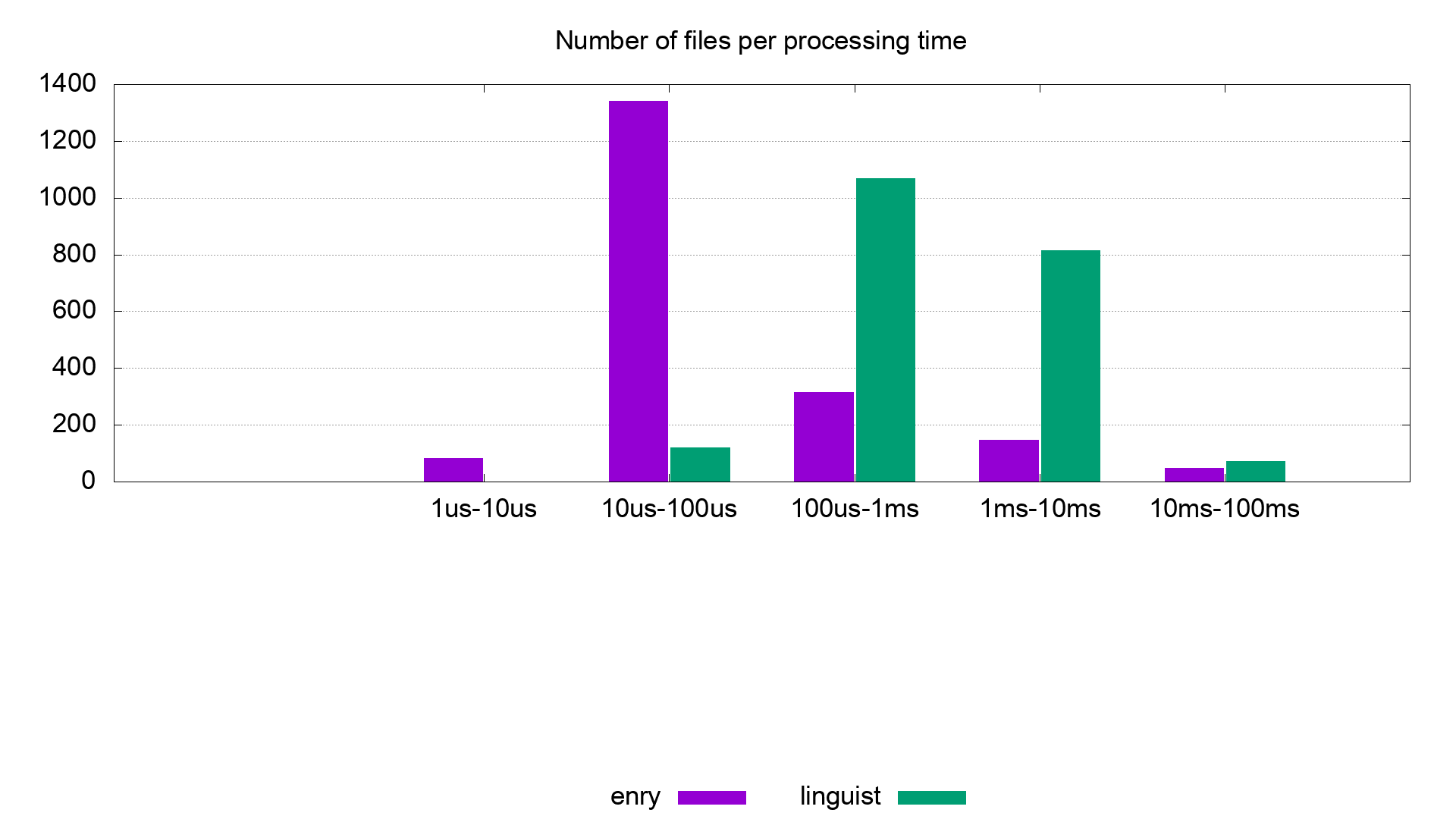
The histogram shows the number of files (y-axis) per time interval bucket (x-axis). Most of the files were detected faster by enry.
There are several cases where enry is slower than Linguist due to Go regexp engine being slower than Ruby's on, wich is based on oniguruma library, written in C.
See instructions for running enry with oniguruma.
Why Enry?
In the movie My Fair Lady, Professor Henry Higgins is a linguist who at the very beginning of the movie enjoys guessing the origin of people based on their accent.
"Enry Iggins" is how Eliza Doolittle, pronounces the name of the Professor.
Development
To run the tests use:
go test ./...
Setting ENRY_TEST_REPO to the path to existing checkout of Linguist will avoid cloning it and sepeed tests up.
Setting ENRY_DEBUG=1 will provide insight in the Bayesian classifier building done by make code-generate.
Sync with github/linguist upstream
enry re-uses parts of the original github/linguist to generate internal data structures. In order to update to the latest release of linguist do:
$ git clone https://github.com/github/linguist.git .linguist
$ cd .linguist; git checkout <release-tag>; cd ..
# put the new release's commit sha in the generator_test.go (to re-generate .gold test fixtures)
# https://github.com/go-enry/go-enry/blob/13d3d66d37a87f23a013246a1b0678c9ee3d524b/internal/code-generator/generator/generator_test.go#L18
$ make code-generate
To stay in sync, enry needs to be updated when a new release of the linguist includes changes to any of the following files:
There is no automation for detecting the changes in the linguist project, so this process above has to be done manually from time to time.
When submitting a pull request syncing up to a new release, please make sure it only contains the changes in the generated files (in data subdirectory).
Separating all the necessary "manual" code changes to a different PR that includes some background description and an update to the documentation on "divergences from linguist" is very much appreciated as it simplifies the maintenance (review/release notes/etc).
Misc
Running a benchmark & faster regexp engine
Benchmark
All benchmark scripts are in benchmarks directory.
Dependencies
As benchmarks depend on Ruby and Github-Linguist gem make sure you have:
- Ruby (e.g using
rbenv),bundlerinstalled - Docker
- native dependencies installed
- Build the gem
cd .linguist && bundle install && rake build_gem && cd - - Install it
gem install --no-rdoc --no-ri --local .linguist/github-linguist-*.gem
Quick benchmark
To run quicker benchmarks
make benchmarks
to get average times for the primary detection function and strategies for the whole samples set. If you want to see measures per sample file use:
make benchmarks-samples
Full benchmark
If you want to reproduce the same benchmarks as reported above:
- Make sure all dependencies are installed
- Install gnuplot (in order to plot the histogram)
- Run
ENRY_TEST_REPO="$PWD/.linguist" benchmarks/run.sh(takes ~15h)
It will run the benchmarks for enry and Linguist, parse the output, create csv files and plot the histogram.
Faster regexp engine (optional)
Oniguruma is CRuby's regular expression engine. It is very fast and performs better than the one built into Go runtime. enry supports swapping between those two engines thanks to rubex project. The typical overall speedup from using Oniguruma is 1.5-2x. However, it requires CGo and the external shared library. On macOS with Homebrew, it is:
brew install oniguruma
On Ubuntu, it is
sudo apt install libonig-dev
To build enry with Oniguruma regexps use the oniguruma build tag
go get -v -t --tags oniguruma ./...
and then rebuild the project.
License
Apache License, Version 2.0. See LICENSE