|
|
||
|---|---|---|
| benchmarks | ||
| cmd/enry | ||
| data | ||
| internal | ||
| java | ||
| regex | ||
| shared | ||
| .gitignore | ||
| .travis.yml | ||
| benchmark_test.go | ||
| classifier.go | ||
| common_test.go | ||
| common.go | ||
| DCO | ||
| enry.go | ||
| LICENSE | ||
| MAINTAINERS | ||
| Makefile | ||
| README.md | ||
| utils_test.go | ||
| utils.go | ||
enry 


File programming language detector and toolbox to ignore binary or vendored files. enry, started as a port to Go of the original linguist Ruby library, that has an improved 2x performance.
Installation
The recommended way to install enry is
go get gopkg.in/src-d/enry.v1/...
To build enry's CLI you must run
make build
this will generate a binary in the project's root directory called enry. You can then move this binary to anywhere in your PATH.
This project is now part of source{d} Engine, which provides the simplest way to get started with a single command. Visit sourced.tech/engine for more information.
Faster regexp engine (optional)
Oniguruma is CRuby's regular expression engine. It is very fast and performs better than the one built into Go runtime. enry supports swapping between those two engines thanks to rubex project. The typical overall speedup from using Oniguruma is 1.5-2x. However, it requires CGo and the external shared library. On macOS with brew, it is
brew install oniguruma
On Ubuntu, it is
sudo apt install libonig-dev
To build enry with Oniguruma regexps use the oniguruma build tag
go get -v -t --tags oniguruma ./...
and then rebuild the project.
Examples
lang, safe := enry.GetLanguageByExtension("foo.go")
fmt.Println(lang, safe)
// result: Go true
lang, safe := enry.GetLanguageByContent("foo.m", []byte("<matlab-code>"))
fmt.Println(lang, safe)
// result: Matlab true
lang, safe := enry.GetLanguageByContent("bar.m", []byte("<objective-c-code>"))
fmt.Println(lang, safe)
// result: Objective-C true
// all strategies together
lang := enry.GetLanguage("foo.cpp", []byte("<cpp-code>"))
// result: C++ true
Note that the returned boolean value safe is set either to true, if there is only one possible language detected, or to false otherwise.
To get a list of possible languages for a given file, you can use the plural version of the detecting functions.
langs := enry.GetLanguages("foo.h", []byte("<cpp-code>"))
// result: []string{"C", "C++", "Objective-C}
langs := enry.GetLanguagesByExtension("foo.asc", []byte("<content>"), nil)
// result: []string{"AGS Script", "AsciiDoc", "Public Key"}
langs := enry.GetLanguagesByFilename("Gemfile", []byte("<content>"), []string{})
// result: []string{"Ruby"}
CLI
You can use enry as a command,
$ enry --help
enry v1.5.0 build: 10-02-2017_14_01_07 commit: 95ef0a6cf3, based on linguist commit: 37979b2
enry, A simple (and faster) implementation of github/linguist
usage: enry <path>
enry [-json] [-breakdown] <path>
enry [-json] [-breakdown]
enry [-version]
and it'll return an output similar to linguist's output,
$ enry
55.56% Shell
22.22% Ruby
11.11% Gnuplot
11.11% Go
but not only the output; its flags are also the same as linguist's ones,
$ enry --breakdown
55.56% Shell
22.22% Ruby
11.11% Gnuplot
11.11% Go
Gnuplot
plot-histogram.gp
Ruby
linguist-samples.rb
linguist-total.rb
Shell
parse.sh
plot-histogram.sh
run-benchmark.sh
run-slow-benchmark.sh
run.sh
Go
parser/main.go
even the JSON flag,
$ enry --json
{"Gnuplot":["plot-histogram.gp"],"Go":["parser/main.go"],"Ruby":["linguist-samples.rb","linguist-total.rb"],"Shell":["parse.sh","plot-histogram.sh","run-benchmark.sh","run-slow-benchmark.sh","run.sh"]}
Note that even if enry's CLI is compatible with linguist's, its main point is that enry doesn't need a git repository to work!
Java bindings
Generated Java bindings using a C-shared library and JNI are located under java
Development
enry re-uses parts of original linguist to generate internal data structures. In order to update to the latest upstream and generate the necessary code you must run:
go generate
We update enry when changes are done in linguist's master branch on the following files:
Currently we don't have any procedure established to automatically detect changes in the linguist project and regenerate the code. So we update the generated code as needed, without any specific criteria.
If you want to update enry because of changes in linguist, you can run the go generate command and do a pull request that only contains the changes in generated files (those files in the subdirectory data).
To run the tests,
make test
Divergences from linguist
Using linguist/samples as a set for the tests, the following issues were found:
-
With hello.ms we can't detect the language (Unix Assembly) because we don't have a matcher in contentMatchers (content.go) for Unix Assembly. Linguist uses this regexp in its code,
elsif /(?<!\S)\.(include|globa?l)\s/.match(data) || /(?<!\/\*)(\A|\n)\s*\.[A-Za-z][_A-Za-z0-9]*:/.match(data.gsub(/"([^\\"]|\\.)*"|'([^\\']|\\.)*'|\\\s*(?:--.*)?\n/, ""))which we can't port.
-
All files for the SQL language fall to the classifier because we don't parse this disambiguator expression for
*.sqlfiles right. This expression doesn't comply with the pattern for the rest in heuristics.rb.
enry CLI tool does not require a full Git repository to be present in filesystem in order to report languages.
Benchmarks
Enry's language detection has been compared with Linguist's one. In order to do that, Linguist's project directory linguist/samples was used as a set of files to run benchmarks against.
We got these results:
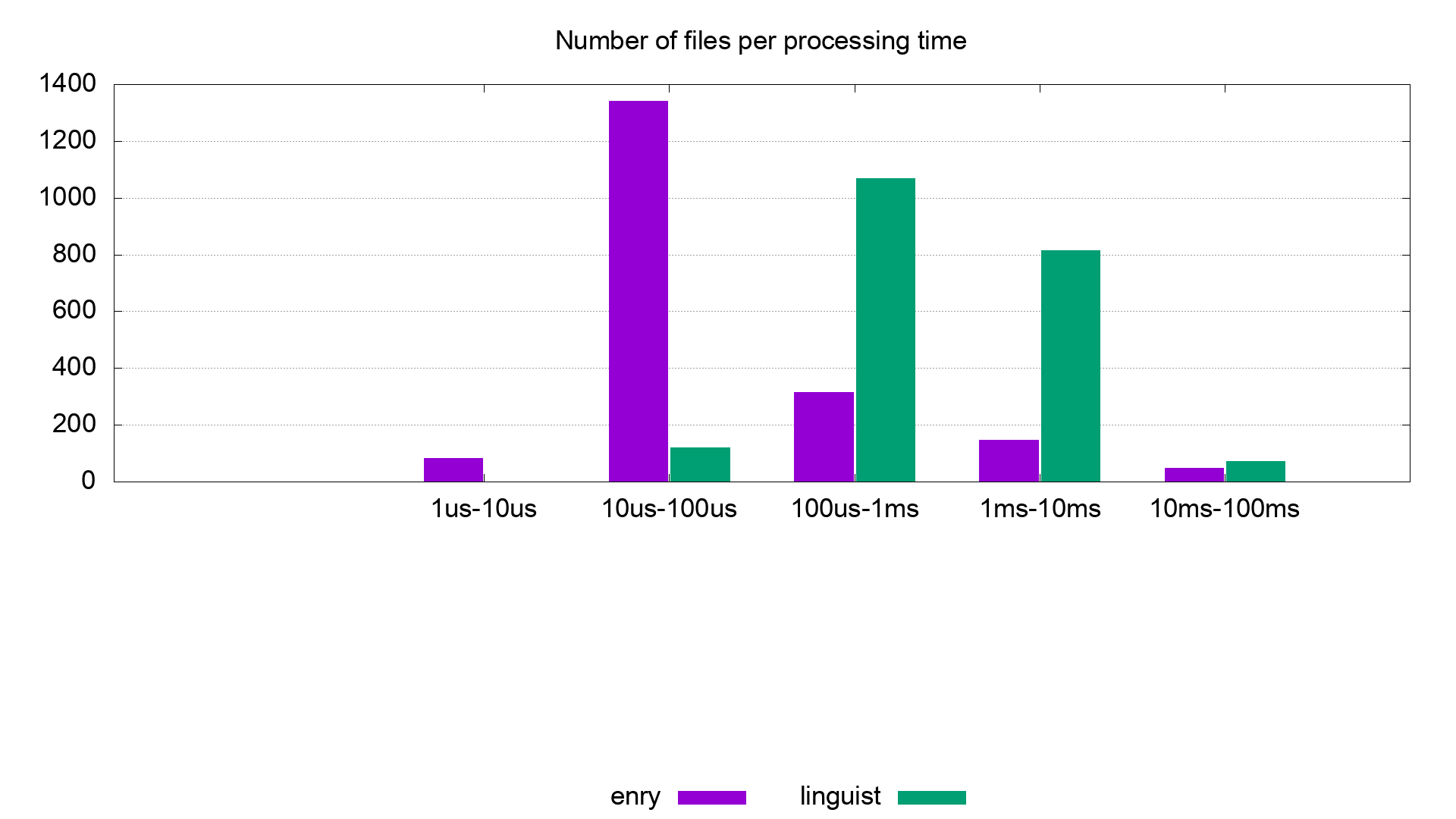
The histogram represents the number of files for which spent time in language detection was in the range of the time interval indicated in the x axis.
So you can see that most of the files were detected quicker in enry.
We found some few cases where enry turns slower than linguist. This is due to Golang's regexp engine being slower than Ruby's, which uses the oniguruma library, written in C.
You can find scripts and additional information (like software and hardware used and benchmarks' results per sample file) in benchmarks directory.
Benchmark Dependencies
As benchmarks depend on Ruby and Github-Linguist gem make sure you have:
- Ruby (e.g using
rbenv),bundlerinstalled - Docker
- native dependencies installed
- Build the gem
cd .linguist && bundle install && rake build_gem && cd - - Install it
gem install --no-rdoc --no-ri --local .linguist/github-linguist-*.gem
How to reproduce current results
If you want to reproduce the same benchmarks as reported above:
- Make sure all dependencies are installed
- Install gnuplot (in order to plot the histogram)
- Run
ENRY_TEST_REPO=.linguist benchmarks/run.sh(takes ~15h)
It will run the benchmarks for enry and linguist, parse the output, create csv files and plot the histogram. This takes some time.
Quick
To run quicker benchmarks you can either:
make benchmarks
to get average times for the main detection function and strategies for the whole samples set or:
make benchmarks-samples
if you want to see measures per sample file.
Why Enry?
In the movie My Fair Lady, Professor Henry Higgins is one of the main characters. Henry is a linguist and at the very beginning of the movie enjoys guessing the origin of people based on their accent.
Enry Iggins is how Eliza Doolittle, pronounces the name of the Professor during the first half of the movie.
License
Apache License, Version 2.0. See LICENSE